在进入主题前,先聊下数据湖这个概念。百度百科中对该名词有如下解释:
数据湖或hub的概念最初是由大数据厂商提出的,表面上看,数据都是承载在基于可向外扩展的HDFS廉价存储硬件之上的。但数据量越大,越需要各种不同种类的存储。最终,所有的企业数据都可以被认为是大数据,但并不是所有的企业数据都是适合存放在廉价的HDFS集群之上的。
说白了,数据湖的意思就是将不同存储类型、不同种类的数据汇聚在一起,例如在一个存储集群中分别有MySQL、Mongodb、s3等等数仓数据,这个存储集群统一对外就是一个数据湖了。
博主所在的项目最近在技术演进中引入了近几年悄然火热的数据湖引擎—Dremio。接下来将通过文章总结下自己对Dremio的理解。
Dremio是新一代的数据湖引擎,它通过直接在云数据湖存储中进行实时的、交互式的查询来释放数据价值。其官网首页第一句话就能很好诠释Dremio真正想要做的事情。
“Set Your Data Free”
“释放你的数据”
Dremio有以下几个主要的特点:
- 快速的数据查询
- 自助式服务语义层
- 灵活并且基于开源技术
- 强大的JOIN性能
根据对Dremio官方Doc的研读和自己的一些项目实践,我挑选了以下Dremio的技术特点,用来展示Dremio的独特:
快速的数据查询
在Dremio中,查询数据是直达数据湖存储的,无论数据是存储在S3、ADLS、Hadoop、MySQL、Mongodb等载体上。Dremio使用了包括不限于以下技术来加速每次的查询:
- Data Reflections
- Columnar Cloud Cache (C3)
- Predictive Pipelining work alongside Apache Arrow
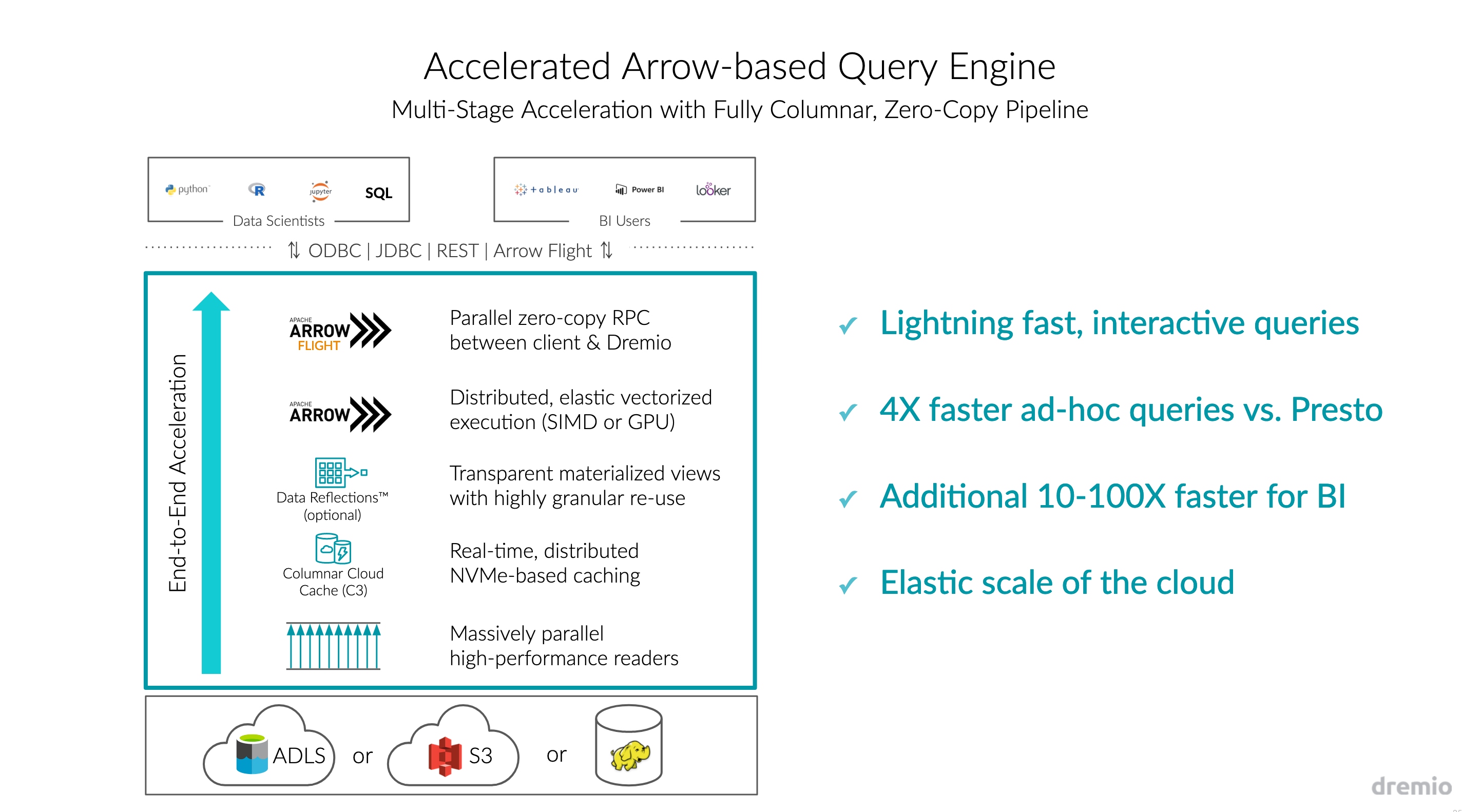
使用Predictive Pipelining和Columnar Cloud Cache(C3)技术加速数据读取
Dremio的Predictive Pipelining技术使得来自数据源的数据只有在执行引擎真正需要到时才会去拉取,这个做法能显著降低引擎等待数据的时间成本。同样地,C3技术则是会自动地在数据存取时将数据缓存到本地的NVMe存储载体,使得查询访问数据湖中的数据能有NVMe存取速度级别的表现。
为云而建造的现代化执行引擎
Dremio的执行引擎是建立在Apache Arrow及其生态技术上的,一个Dremio集群能够根据存储数据的体量规模弹性伸缩。
Data Reflections - 能够更高效查询速度的开关
通过在Dremio提供的客户端页面的几下点击,就能够创建反射,反射是一种物理层面上对数据结构的优化,能够加速各种查询模式,根据你的需要可以创建任意数量的反射,Dremio会隐形并自动地在查询计划中合并反射,并保证查询到最新数据。
Arrow Flight - 以1000x的倍速移动数据
AF被设计出来是用于取代处理小规模数据的ODBC和JDBC协议,AF在高速、分布式传输协议的基础上,为Dremio和应用的数据传输提供了1000x倍速度提升的吞吐。
自助式服务语义层
Dremio提供了一个应用安全和商业意义的抽象层,以支持用户能够探索数据,以及派生出新的虚拟数据集。
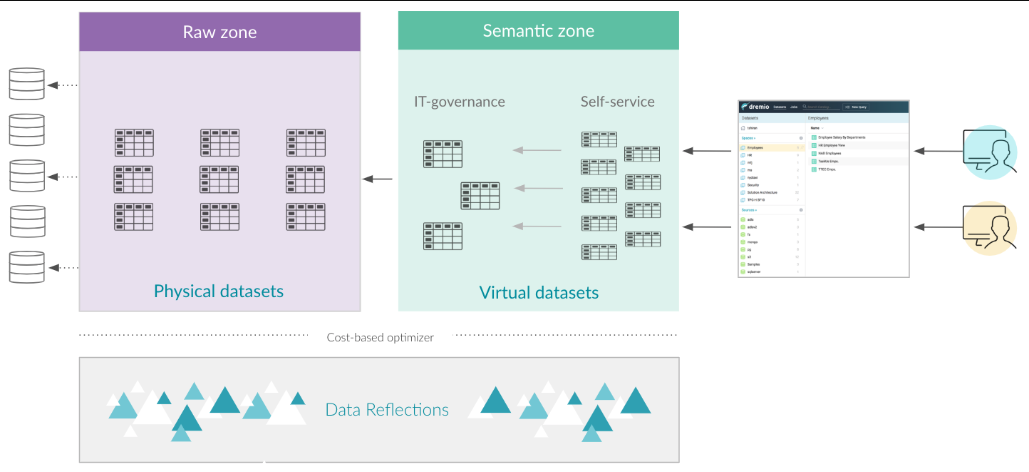
可自定义化的语义抽象层
Dremio的语义层是一个能够索引出所有用户元数据的集成化、可搜索的目录。在此语义层上,虚拟数据集以及空间构成了语义层,并且都是能够倍索引和搜索的。
高效的数据上下文管理
通过虚拟上下文的管理,Dremio让可以使得筛选、转换、联表、聚合一个或多个数据源的数据变得快速,容易并且成本低。另外,Dremio的虚拟数据集是通过标准SQL定义的,如此我们使用起来旧不需要再另外学习一套查询语法了。
直接应用在BI或数据科学工具上
Dremio其实就如同关系型数据库一样,并且Dremio可以暴露ODBC、JDBC、REST以及Arrow Flight协议的接口,这样我们就可以在一些BI应用上连接Dremio获取数据。
细粒度的访问权限控制
Dremio提供行级和列级的权限控制,可以让我们基于敏感数据、基于角色来控制对数据的访问权限。
数据血缘
Dremio的data graph管理着数据源、虚拟数据集以及查询语句之间的关系,我们可以通过data graph获知到当前查询的数据集的来源。